Gaussian Discriminative Analysis
If I sample many many apples from a basket of independent identically distributed (i.i.d.) randomly sized appels, the distribution of the size of my apples will converge towards the Gaussian distribution. This is what Laplace came up with in 1812, in his “Analytic Theory of Probability”. Although Carl Friedrich Gauss 3 years before that already introduced the function and worked out the least squares approximation to estimate the ’true’ (mean) value from a bunch of i.i.d. measurements (very usefull in statistics / confidence calculations).
1D Gaussian
Now lets get back to machine learning …. We can use a the Gaussian distribution to model the PDF of features. And if you remember, we can use Bayes’ theorom to caculate the posterior distribution from the PDF and so we can make a prediction algorithm!
Parametric Density Estimation: To get an idea of the underlying distribution of the features we try to estimate this distribution based on a formula with parameters. Most commenly used formula for parametric density estimation is the Gaussian distribution:
Quadratic discriminate analysis
Lets say we only have two features of Fishers’ Iris dataset available, for example petal length and sepal length and we are only dealing with two species instead of three (making the example as easy as possible to visualize it).
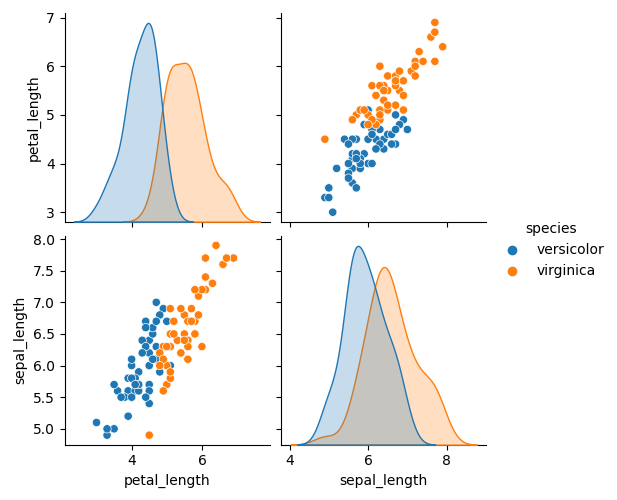
The Quadratic discriminate analysis is an algorithm that predicts the species based on the two features. This does require the multivariate version of the Gaussian so let’s have a look:
Multivariate Gaussian
In binary (two species) QDA the classification is based on the discriminant:
A positive discriminant means the posterior probability of class 1 is higher and thus we classify $x$ as class 1. The log of the posterior probabilities is taken because this yields a simpler (more efficient) equation. This is possible because log is a monotonically increasing function, which means that the relations of order are unchanged. The $max_i$ $p(y_i|x)$ will also be the $max_i$ log $p(y_i|x)$. From the log of the posterior probability follows:
Removing all non-class dependent constants yields:
Plugging the result into the discriminant equation yields:
This is a quadratic equation modeling the decision boundary for a two class classification problem. The final class prediction or hypothesis $h(x)$ is then given by the following bernouilli distribution.
Linear discriminate analysis
Given the assumption that the covariance matrices of both classes are equal $(\Sigma_1 == \Sigma_2)$, the decision boundary becomes linear:
Also called Fisher’s Linear Discriminate analysis.
Fisher Iris Example
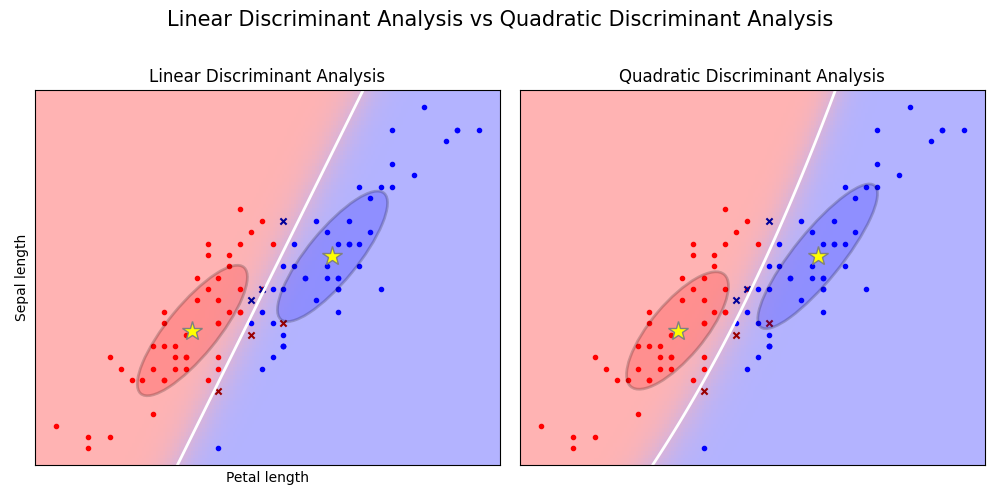
Code for this was taken from: https://scikit-learn.org/stable/auto_examples/classification/plot_lda_qda.html#sphx-glr-auto-examples-classification-plot-lda-qda-py
Side Note: LDA as a dimensionality reduction technique
In Fisher’s article he observes that at the decision boundary (discriminant = 0), the ratio of between and within class variance is:
Here $\omega$ is a unit vector in a certain direction. He furthermore obeserves that this ratio is maximal for, $\omega$ as in LDA:
The simple interpretation of this is that, the dicision boundary has a slope which is equal to the direction of maximum $\Phi$.
The use LDA as a dimensionality reduction technique all you have to do is map the data onto the first $k$ principal axes of the $\Phi$. (Later on we will have a look at other similar dimensionality reduction technique such as PCA)
Conclusion
We’ve looked at two variants of parametric generative algorithms to predict flower species from petal / sepal lengths. For our small test example lda and qda were quite alright, but it’s good to know what the limitations are.
QDA assumptions/limitations:
- It assumes the PDF of the class conditional distributions can be modelled by a Gaussian.
- The decision boundary generated by QDA is quadratic.
- It uses Bayes’ rule to get from class conditional distributions to posterior distribution and to achieve this the class priors are used. So for datasets with imbalanced example count per class this can induce a bias for a specific class with a higher example count.
LDA assumptions/limitations:
- Like Qda, it assumes the PDF of the class conditional distributions can be modelled by a Gaussian, but it goes one step further by assuming that all classes share a PDF with the same covariance matrix.
- The decision boundary generated by LDA is linear.
- It uses Bayes’ rule to get from class conditional distributions to posterior distribution and to achieve this the class priors are used. So for datasets with imbalanced example count per class this can induce a bias for a specific class with a higher example count.