Logistic Regression
Logistic regression
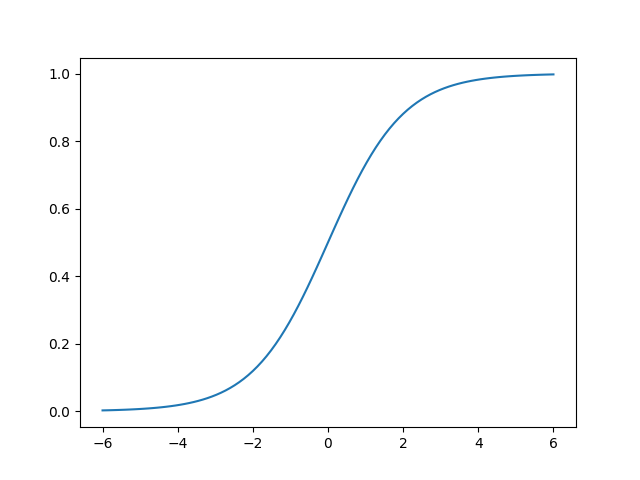
Logistic regression unlike linear regression is well suited for classification type problems. The difference lies in the way data is fitted, instead of a linear (hyper)plane it is fitted using the following exponential function (also known as the sigmoid function):
This function has the nice property that, its output is bound between zero and one. This is a usefull property when trying to model the (posterior) probability of something. In a two class classification problem, where the output is either a one or a zero, a bounded function intuitively also makes more sence.
The derivative of $h_{\theta}(x)$ is going to be usefull later on, for gradient descend.
Cost function
In a two class binary classification example the posterior probability of the logistic regression function is modeled using the bernoulli distribution:
The cost function for the logistic regression method will again be formulated based on the likelihood of the data given the parameter $\theta$. The Likelihood is defined as the cumulitive probability of the correct class for all given training objects. The likelihood of a dataset (assuming samples were drawn independently):
To use this likelihood in our gradient descend alogrithm we will transform it in the following way. Because the gradient descend algorithm optimizes for finding the minimum cost, we will have to take the negative likelihood. Taking the log of the likelihood will make computations a lot easier without affecting the outcome. Another reason for taking the log of the likelihood is to prevent the likelihood from converging towards zero very quickly as the dataset volume increases.
Gradient descend
The update rule for our stochastic gradient descend (one training example) algorithm will look as follows: